The Art of Data Sharing: key in future climate science
Aurora Elmore1, F. Lehner2 and J. Franke2
 |
|
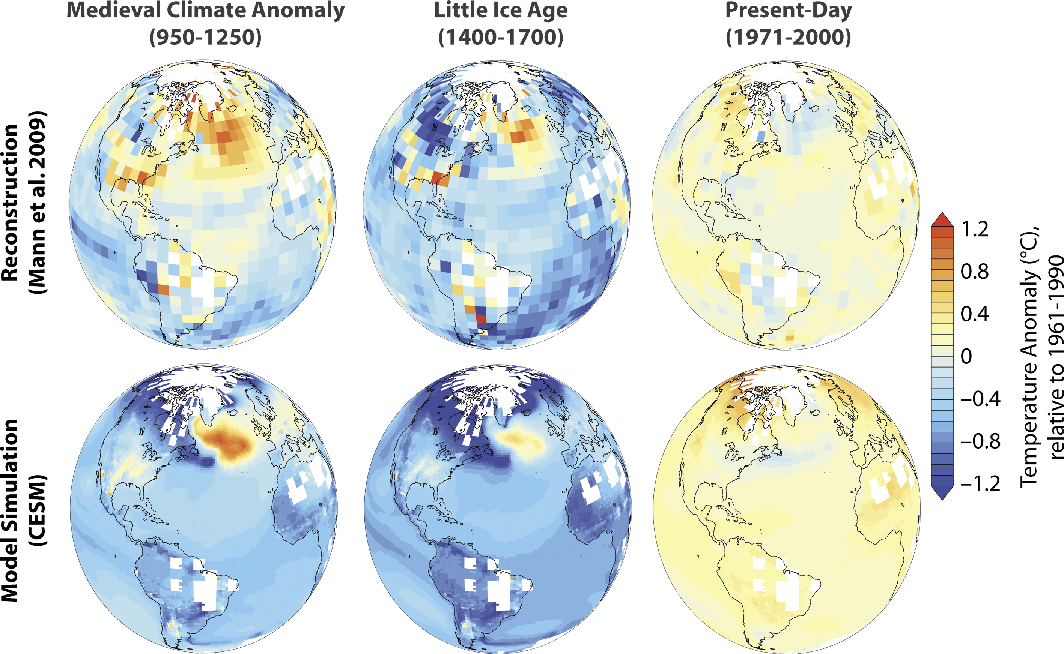
Figure 1: Sharing and combining data and model simulations allows for a better understanding of past climate variability. Temperature anomalies relative to 1961-1990 in a reconstruction (Mann et al. 2009) and a Last Millennium simulation with a comprehensive coupled model (Community Earth System Model). White areas indicate no reconstruction data; the same areas have been masked in the model output for comparability. |
At the PAGES Young Scientists Meeting, 11-12 February 2013, in Goa, India, 79 young researchers from around the world gathered to discuss research, to network, and to exchange ideas for the future of climate research. Initiated by a talk on “The Art of Data Sharing” given by David Anderson, head of the World Data Center for Paleoclimatology at the National Oceanic and Atmospheric Administration (NOAA), a lively discussion arose on the benefits and potential of data sharing for future research.
Fortunately, many researchers already upload their data and computer code to an Internet database to be available for future projects. Therefore, a wealth of databases and software exist that are open and easily accessible (see Box 1). These include data from classical proxy archives such as tree rings, ice cores, lake and marine sediments, as well as model output, reanalysis, observations and a multitude of free algorithms, scripts and software packages.
Not only can researchers use these archives to compare with their own new data, but also groundbreaking studies seeing the large-scale picture can result from compiling or reanalyzing existing data sets (e.g. Lisiecki and Raymo 2005; Mann et al. 2008; Andrews et al. 2012). These kinds of data compilation projects are time-intensive. However, when fed back to the database, the resulting data can be highly beneficial for the paleoscience community as it avoids duplication of effort. Data compilation efforts can also be funding-efficient, as some funding agencies have already requested proposals specifically based on that approach. Some general ideas for future compilation-style research include time-slice reconstructions and comparison between transient model simulations and sensitivity experiments conducted by different institutes.
So, why do not all researchers share their data?
The idea of being “scooped” seems to be one of the most important fears preventing researchers from uploading their published data; this seems to be particularly important for young researchers who are working towards establishing their careers and thus cannot afford to not be credited for their work. But in reality, such cases occur rarely and the vast majority of scientists sharing their data experience only benefits from it, including more citations and often even additional co-authorships.
Another barrier to uploading research data seems to be the author's worry about data being misused or misrepresented. Providing detailed meta-information about the data and corresponding error bars greatly reduces the risk of inappropriate use of data. However, the largest hindrance seems to result from confusion about which data repository to use and how to format the data. To this end, many data repositories have helpful “read-me” files and staff support to help with the uploading, so that the researcher hardly has to spend much additional effort.
Some journals and funding agencies are now mandating that authors archive data that appear in publications and discussants at the YSM were united in their hope that this trend towards open access continues.
One way to encourage and credit data sharing in the future could be in the form of a “data citation index”. Usually, data compilation studies do not cite every individual data paper that went into the compilation - mainly to prevent the bibliography from exploding. A “data citation index”, following the example of the classical citation index for papers, could provide an efficient way of crediting the papers underlying data compilation studies without generating lengthy bibliographies.
With limitless potential for compilation studies to generate truly innovative science and the relative ease of uploading data, we hope many readers consider using these great resources and, of course, helping them to grow.
affiliations
1Department of Geography, Durham University, UK; aurora.elmore durham.ac.uk
durham.ac.uk
2Oeschger Centre for Climate Change Research, University of Bern, Switzerland
references
Andrews T et al. (2012) Geophysical Research Letters 39, doi: 10.1029/2012GL051607
Lisiecki LE, ME Raymo (2005) Paleoceanography 20: 1-17
Box 1: Examples of databases, software, and sample repositories.
The number of databases, open-source software and repositories is growing, providing extensive resources for scientists to engage in data-intensive research.
Databases
Pangaea, Data publisher for Earth & Environmental sciences, www.pangaea.de
World Data Center for Paleoclimatology,www.ncdc.noaa.gov/paleo
Neotoma, A paleoecology database and community, www.neotomadb.org
JANUS, Data from the Integrated Ocean Drilling Program, www-odp.tamu.edu/database
Core Curator’s Database, the Index to Marine and Lacustrine Samples, www.ngdc.noaa.gov/mgg/curator
PAGES list of databases, www.pastglobalchanges.org/my-pages/data
Software
Calib, the radiocarbon calibration program, http://calib.qub.ac.uk/calib
Analogue, Analogue and weighted-averaging methods for paleoecology, http://analogue.r-forge.r-project.org
Singular Spectrum Analysis, A toolkit for spectral analysis, www.atmos.ucla.edu/tcd/ssa
Ocean Data View, a software package for the exploration and analysis of oceanographic and other data, http://odv.awi.de
KNMI Climate Explorer, an online tool to visualize and analyze climate data with a large ready-to-use database, climexp.knmi.nl