PAGES Magazine articles
Michael Diepenbroek
Initiated in the 1990s, PANGAEA1 has evolved from a paleoclimate-data archive to a multidisciplinary data publisher for Earth and environmental sciences, accredited as a World Data Center by the International Council for Science World Data System (ICSU WDS)2 and as World Radiation Monitoring Center (WRMC)3 within the World Meteorological Organization Information System (WIS)4.
Even in its earliest stages, data were archived consistently and carefully curated. This involves cleaning, harmonizing, and integrating data, as well as metadata, within PANGAEA’s editorial workflow. Consequently, all data sets are annotated including information on how, when, and where they were produced, information about principal investigators, measurement and observation types, sampling and analysis methods, and devices as well as references to literature. In January 2005, the first data sets were registered and minted with a standard-compliant Digital Object Identifier (DOI), which enables proper citation of data and their integration within the publishing-industry workflow and bibliometric analyses. Today, PANGAEA holds around 375’000 citable data sets comprising more than 13 billion data items - numerical and textual data as well as binaries such as images, videos, or files with community specific mime types. Each data item is a georeferenced record including the parameter value, parameter type, and the spatial and temporal coverage; spatio-temporal values themselves are not data items. Over 18% of published data sets include at least one author linked to ORCID (the author identifier of the publishing industry). PANGAEA is operated as an Open Access library and is open to any project, institution, or individual scientist to use or to archive and publish data5.
As paleoclimate research is the scientific background of PANGAEA’s founders, it has a long-lasting relationship with PAGES and also looks back to a long-standing collaboration with the NOAA WDS-Paleo. The recent common focus is on interoperability and findability of paleodata. Both data centers build the archive backbone for paleodata. PANGAEA holds large inventories of all types of paleodata, for example isotope and geochemical data as well as pollen and tree-ring data. An example data collection is the data collected by the PAGES C-PEAT working group6.
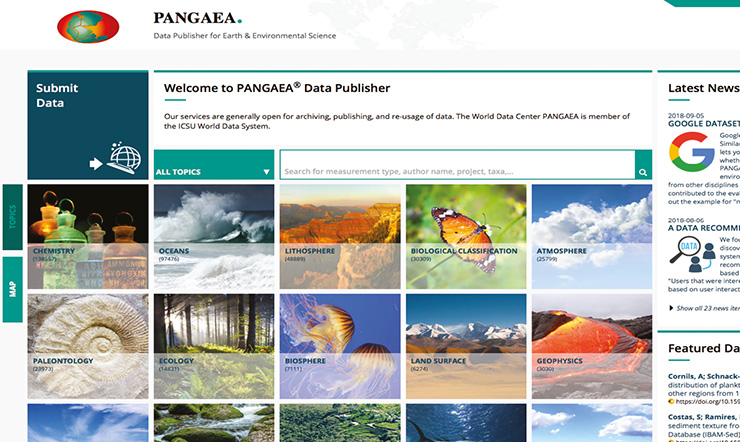 |
|
Figure 1: PANGAEA’s website offers various ways to search for data. |
Editorial
PANGAEA is operated by a team of data editors, project managers, and IT specialists7. Our editors are scientists with expertise in all fields of Earth and environmental science. They have a deep knowledge of the review and processing of scientific data. The PANGAEA data editorial ensures the integrity and authenticity as well as a high reusability of data. Archived data are machine readable and mirrored into our data warehouse which allows efficient compilations and downloads of data8.
Data are submitted using a ticket system (Jira9) and assigned to an editor who is a specialist in the corresponding data domain. Preparation of the data for import is done with a highly sophisticated editorial system. Data editors check the completeness and validity of data and metadata, reformat data according to the PANGAEA ingest format, and harmonize data and metadata using standard terminologies (Diepenbroek et al. 2017). The editorial review is complemented by inviting authors and external reviewers (e.g. reviewers of articles supplemented by the data) to proofread the data sets. After being accepted, the data sets are archived, provided with a DOI, and registered at DataCite10.
Interoperability and findability
PANGAEA is furnished with a well-developed interoperability framework based on internationally accepted standards. All interfaces to the information system are based on web services including map support (Google Earth, Google Maps)11. This allows most effective dissemination of metadata and data to all major internet search-engine registries, library catalogues, data portals, and other service providers, and consequently ensures the optimal findability of data hosted by PANGAEA. Scientific data portals supported include DataOne, GEOSS12, the ICSU WDS2, GBIF13 and also the paleo data portal at NCEI14. Other infrastructures supported include DataCite15, ORCID16, and Scholix17, which supplies links between scholarly literature and data. Interoperability with ORCID allows users to login with their ORCID ID and link it to their user profile in PANGAEA. In this way, data publications are automatically assigned to matching ORCID IDs.
affiliation
MARUM - Center for Marine Environmental Sciences, University Bremen, Germany
contact
Michael Diepenbroek: mdiepenbroek pangaea.de
pangaea.de
references
Diepenbroek M et al. (2017) J Biotech 261: 177-186
links
6pangaea.de/?q=project%3Alabel%3APAGES_C-PEAT
9en.wikipedia.org/wiki/Jira_(software)
13gbif.org
Wendy Gross1, C. Morrill1,2 and E. Wahl1
Guided by FAIR principles as best data management practices (Wilkinson et al. 2016), the World Data Service for Paleoclimatology (WDS-Paleo) at NOAA’s National Centers for Environmental Information (NCEI) has recently deployed new capabilities and data-format standards. These and planned future developments facilitate the standardization and aggregation of WDS-Paleo’s small, long-tail, and heterogeneous datasets into larger standardized collections. These capacities enhance the value of the data, analogous to how large volumes of well-managed big data can be transformed into valuable information (Lehnert and Hsu 2015).
WDS-Paleo archives and provides paleo-climatology data products derived from a variety of sources, such as tree rings, ice cores, corals, and ocean and lake sediments, along with web-based services to access these products. To attain the goal of long-term professional preservation and dissemination of its data, WDS-Paleo partners with its user communities and maintains long-standing relationships with PAGES, PANGAEA and Neotoma. WDS-Paleo works with these partners to offer aggregated search capabilities. NCEI data stewardship operations meet the responsibilities of an Open Archival Information System (oais.info), and new and existing capabilities follow FAIR best practices as follows.
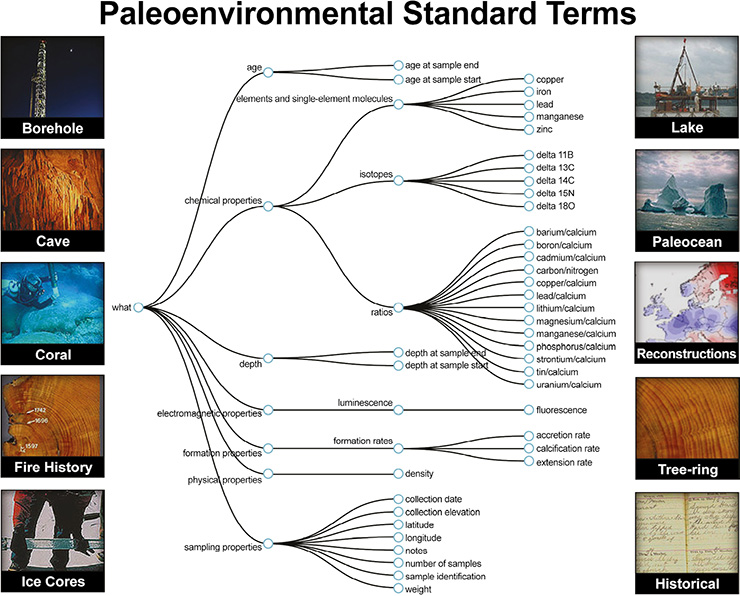 |
|
Figure 1: Example of Paleoenvironmental Standardized Terms (PaST) controlled vocabulary. |
Findable
WDS-Paleo makes its data findable via geographic map-based searches, along with a web service featuring an application programing interface (API) for programmatic use and a graphical user interface (GUI) that also acts as an API-builder tool (ncdc.noaa.gov/paleo-search). Recently a new controlled vocabulary, Paleoenvironmental Standard Terms (PaST; ncdc.noaa.gov/data-access/paleoclimatology-data/past-thesaurus) has been developed for documenting variables (i.e. paleoclimate measurements, units and methods). With the input of 25 subject-matter experts, terms have been assigned to over 100,000 paleoclimatic time series, powering new search capabilities that complement other web-service features. Paleoclimate data are extremely heterogeneous, and with PaST terminology WDS-Paleo’s search capabilities now capture this heterogeneity. In the future, interactive visualizations of PaST will allow users to obtain more-detailed information about terms and will enhance data discovery. The governance structure for PaST is described at the above link.
Accessible
A recently released feature of the WDS-Paleo web service provides users with capacity to bundle and download search results, thus easing the process of procuring sets of data appropriate for specific use. A bundle includes data files and manifest information, maintaining provenance of both data and metadata.
Interoperable
Upcoming and long-standing data and metadata formats promote interoperability via machine readability and common tools. Going ahead, a NOAA Standard for the Linked Paleo Data Format (LiPD, lipd.net) (now in development), is designed to facilitate interoperability between LiPD and the NOAA WDS-Paleo Template data format, including use of PaST terms. Standardized metadata formats, including DIF, ISO, and JSON, facilitate data discovery and federated search capabilities. Community-specific data formats and software tools, including those developed and used by the International Tree Ring Databank (ITRDB) and International Multiproxy Paleofire Database (IMPD), provide key resources for scientific discovery.
Reusable
PaST-enhanced web-service search capabilities aggregate WDS-Paleo’s small, long-tailed datasets into larger, standardized collections. This can facilitate large-scale data syntheses, which is a key thrust in paleoclimatology (e.g. PAGES 2k Consortium 2017), and also promotes reuse of paleo data beyond paleoclimate specialists. WDS-Paleo is implementing persistent identifiers and locators for datasets via the provision of DOIs.
Going forward, PaST and a future project of standardizing the reporting of age determination will greatly enhance the interoperability of WDS-Paleo data formats, allowing for easier and more robust aggregation of datasets.
The WDS-Paleo website, including search, access, data contribution, and PaST information is at: ncdc.noaa.gov/paleo
affiliations
1NOAA’s National Centers for Environmental Information, Boulder, USA
2Cooperative Institute for Research in Environmental Sciences (CIRES), University of Colorado Boulder, USA
contact
WDS-Paleo: paleonoaa.gov
references
Lehnert K, Hsu L (2015) 11: 368-369
Belmont Forum e-Infrastructures & Data Management Project
The Belmont Forum partnership of funding organizations, and international and regional science councils, is committed to accelerating open-data sharing and reuse by improving researchers’ data-management practices, solving e-infrastructure challenges and improving the data skills of global environmental-change scientists.
The Belmont Forum1 is a partnership of national science funding organizations, international science councils, and regional consortia across the world committed to the advancement of global environmental science (Fig. 1). The partnership aims to accelerate delivery of data-driven environmental research to remove critical barriers to sustainability by aligning and mobilizing international resources.
The Belmont Forum activities are driven by the Belmont Challenge2 that encourages international transdisciplinary research to provide knowledge for understanding, mitigating and adapting to global environmental change. The Belmont Forum supports multi-national and transdisciplinary collaborative research through Collaborative Research Actions (CRAs)3, bringing together natural sciences, social sciences and the humanities, as well as stakeholders, to co-create knowledge and solutions for sustainable development.
Global environmental-change research increasingly requires integrating large amounts of diverse data across scientific disciplines to deliver the policy-relevant and decision-focused knowledge that societies require to respond and adapt to global environmental change and extreme hazards, to manage natural resources responsibly, to grow our economies, and to limit or even escape the effects of poverty. To carry out this research, data need to be discoverable, accessible, usable, curated, and preserved for the long term. This needs to be done within a supporting data-intensive e-infrastructure framework that enables data exploitation, and that evolves in response to research needs and technological innovation. Without open data and the supporting e-infrastructure, policy makers and scientists will be forced to feel their way into the future without the benefit of new scientific understanding; unfocused and ill-prepared.
To accelerate the openness, accessibility and reuse of data from CRA projects, the Belmont Forum adopted an Open Data Policy and Principles4 to stimulate new approaches to the collection, reuse, analysis, validation, and management of data, digital outputs and information, thus increasing the transparency of the research process and robustness of the results. In 2015, the Forum established the e-Infrastructures & Data Management (e-I&DM) Project5 to help implement the Open Data Policy and reduce barriers to data sharing and interoperability. e-I&DM is promulgating procedures, standards, workflows, and other elements critical to identifying a path toward cooperative e-infrastructures and data-management policies and practices that enable and accelerate open access to, and reuse of, transdisciplinary research data.
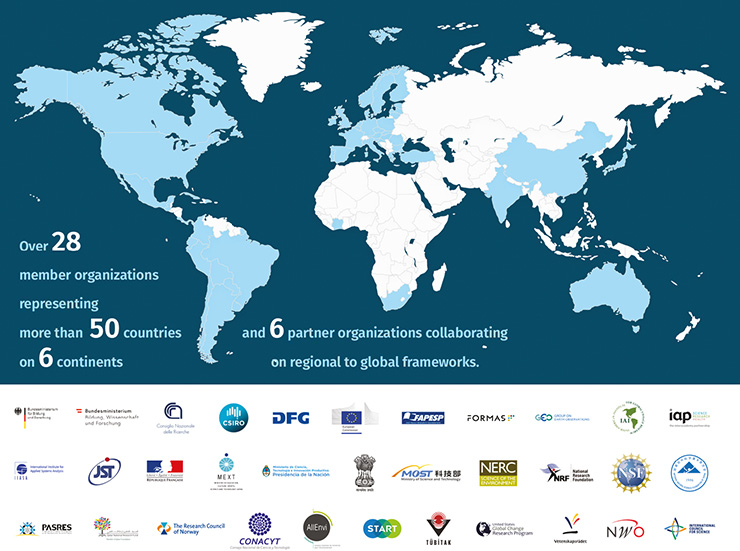 |
|
Figure 1: Belmont Forum: An International Partnership of Funding Agencies and Science Councils. |
Implementing data management for openness and reuse
The Belmont Forum is gradually implementing its Open Data Policy through its CRA funding process. All CRA calls now require a data management plan (Data and Digital Outputs Management Annex6) to ensure that project teams will meet both the Open Data Policy and Principles and the Force11 FAIR (Findable, Accessible, Interoperable and Reproducible) Data Principles7, and adhere to relevant standards and community best practices. Belmont Forum researchers must consider data-management issues from the inception of a project in order to plan and budget appropriately for data curation, management and sharing. Data-management plans should also comply with public-access policies and applicable national laws of the respective funding agencies supporting CRA awards.
Research data and digital outputs are expected to be open by default and publicly accessible, possibly after a short period of exclusivity, unless there are legitimate reasons to constrain access. Data and digital outputs must be discoverable through machine-readable catalogues, information systems and search engines. A full Data and Digital Outputs Management Plan for an awarded Belmont Forum project is expected to be a living, actively updated document that describes the data-management lifecycle for the data and other digital outputs collected, processed, or reused.
A related e-I&DM initiative is a collaboration between Belmont Forum funding agencies and science publishers to articulate a coherent set of data and digital-outputs-management expectations for published research, with the ultimate result of improved sharing and data reuse. Now approved by the Belmont Forum Plenary, the Data Accessibility Statement language will be incorporated into the Data and Digital Outputs Management Annex, so researchers will understand the end-to-end expectations of both funders and publishers regarding management of their research data to maximize openness, accessibility, and reuse.
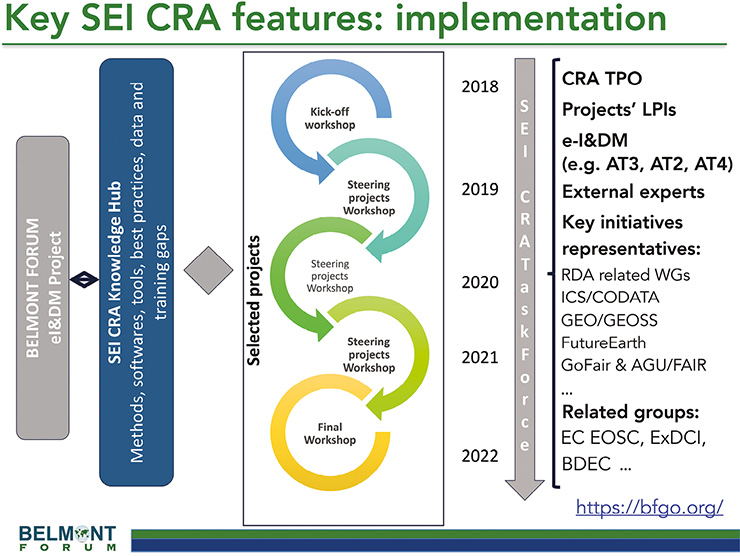 |
|
Figure 2: A "Task Force" will steer the SEI CRA implementation in synergy with the Belmont Forum e-Infrastructures & Data Management Project, continuously monitoring the progress and activities of the funded projects through regular workshops, fostering collaboration and maximizing the outcomes across projects. This will contribute to a knowledge Hub catalyzing research efficiently through sharing of best practices, methods and software implementations, to allow delivery of recommendations and priorities to the Belmont Forum for transnational federated data e-infrastructures, data policies and capacity building. |
Addressing the barriers to transnational data sharing and reuse
The capability is emerging to bring computer science and technology, as well as large and complex data sets, to bear on interdisciplinary and transdisciplinary science. It is therefore critically important to establish and enable transnational frameworks so that data-driven scientific knowledge can transcend both disciplinary and geographical borders, ultimately increasing the scientific underpinnings of policy and action. International collaboration within the Belmont Forum research priorities holds the potential to establish international foundations for federated data integration and analysis systems with shared services. It can also bring together best practices from the public and private sectors, foster open-data and open-science stewardship among the science communities, including related areas such as publishing, and encourage data and cloud providers and others to adopt common standards and practices for the benefit of all.
For these reasons, the Belmont Forum recently closed a four-year competitive call on Science-driven e-Infrastructure Innovation (SEI) for the Enhancement of Transnational, Interdisciplinary and Transdisciplinary Data Use in Environmental Change8. The SEI call will fund initiatives that bring together environmental, social, and economic scientists with data scientists, computational scientists, and e-infrastructure and cyberinfrastructure developers and providers to solve methodological, technological and/or procedural challenges currently facing interdisciplinary and transdisciplinary environmental-change research.
The SEI call is being implemented under a “task force” structure (Fig. 2) that requires all funded projects to share results, participate in annual steering workshops, and contribute to a knowledge hub that will catalyze efficient research through sharing of best practices, methods and software implementations. Information in the knowledge hub may also be used to deliver research-driven recommendations to the Belmont Forum to address needs or enhance current strategies for transnational federated data e-infrastructures, data policies and capacity building.
Building researchers' data skills
The Belmont Forum e-I&DM strategy document, ‘A Place to Stand’9, recommended that a “cross-disciplinary training curriculum was required to expand human capacity in technology and data-intensive analysis methods for global change research” and that a new data literacy was required for the 21st century. Consequently, the e-I&DM Project developed the Data Skills Curricula Framework10, based on a global survey11 (Skills Gap Analysis), data skills workshop12 and extensive consultation with data-management experts and trainers.
The Curricula Framework outlines core modules to enhance the skills of domain scientists specifically to make data handling more efficient, research more reproducible and data more shareable – including visualizations for end-users. The five core skills comprise programing, particulars of environmental data, visualization, data management, and interdisciplinary data exchange. Further, a number of optional modules are suggested for more-established researchers as useful introductions to widen their data skills, such as machine learning and object-oriented programing. Two additional modules aim to provide Principal Investigators with an overview of data management and skills needed for open data.
Of the core curricula, the two skill areas addressed least by existing training are ‘Environmental data: expectations and limitations’ and ‘Interdisciplinary data exchange’. Since materials on the former are likely to exist in university courses, ‘Interdisciplinary data exchange’ is the current focus of the Belmont Forum, to be taught in a mixed class of environmental scientists, social scientists and engineers.
To build on existing capabilities, e-I&DM is investigating the training activities currently available from Belmont Forum member agencies. In addition, e-I&DM is working closely with the data-science community to identify existing training offerings available from around the world and augment content and provision of courses as needed.
Taken as a whole, the Belmont Forum’s focus on data management, e-infrastructures and data skills is a critical step forward in advancing open-data sharing, data accessibility and data reuse.
affiliation
Belmont Forum e-Infrastructures and Data Management Project, Montevideo, Uruguay
contact
Links
2belmontforum.org/wp-content/uploads/2017/04/belmont-challenge-white-paper.pdf
4belmontforum.org/about/open-data-policy-and-principles/
7force11.org/group/fairgroup/fairprinciples
8bfgo.org/opportunity/index.jsp#sei2018
10bfe-inf.org/sites/default/files/doc-repository/Outline_Data_Skills_Curricula_Framework.pdf
11bfe-inf.org/sites/default/files/doc-repository/BF-Skills-Gap_Analysis-2017_0.pdf
Alexander Koch1, K.C. Glover2, B. Zambri3, E.K. Thomas4, X. Benito5 and J.Z. Yang6
We conducted a survey on open-data-sharing experiences among early-career researchers (ECRs). While ECRs feel open-data sharing benefits their career, insufficient training in data stewardship presents a substantial challenge to data reusability.
Paleoclimate researchers readily acknowledge the benefits of open data, while identifying the need to improve best practices for data archival and sharing (Kaufman and PAGES 2k special-issue editorial team 2018). Growing data repositories are especially beneficial for ECRs, enabling the pursuit of synthetic, large-scale research questions from the start of their career. Fully implementing open-data practices throughout a project’s lifecycle, however, remains time consuming and challenging.
We sought to understand how these challenges relate specifically to ECRs, and summarize here the results from a recent survey. Our survey was designed around the following questions:
• What challenges do ECRs face in following open-data practices?
• Do ECRs perceive open-data practices as advantageous?
• How can open-data practices enable ECRs’ long-term scientific objectives?
While open-data practices are overwhelmingly perceived as advantageous for both one’s long-term career and the advancement of science, our results highlight that the largest challenges to ECR implementation include unfamiliarity with community norms, and a lack of training and support. This perspective should inform the community’s work towards greater standardization and rigor for open-data-sharing practices.
 |
|
Figure 1: Selected survey demographics. |
Methods
The anonymous survey consisted of 30 multiple-choice and free-response questions (see Suppl. Information). We wrote questions to target concerns raised in an ECR forum on open-data experiences (PAGES Early-Career Network 2018), and in consideration of the interactive discussion phase of the PAGES 2k Network open-data-implementation-pilot manuscript in the journal Climate of the Past (Kaufman and PAGES 2k special-issue editorial team 2018). Here we define ECRs as non-tenured survey respondents, since achieving tenure is unlikely within five years after PhD completion. We used Qualtrics as our survey platform, and disseminated the survey via paleoscience listservers (e.g. ECN-list; pmip-announce; paleoclimate-list; paleolim-list; Ecolog-list), Twitter, and word of mouth. The survey was open for 17 days, from 31 May to 17 June 2018.
 |
|
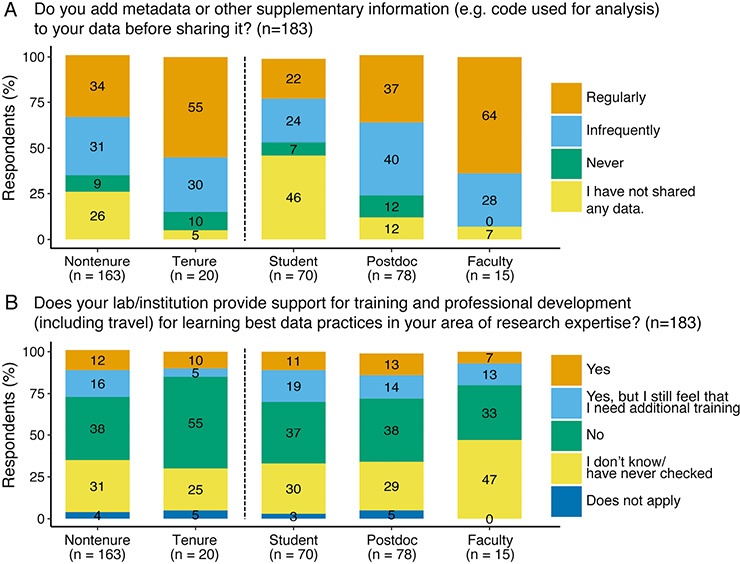
Figure 2: Selected survey responses (%; n=183) grouped by research experience. Non-tenure encompasses student, postdoc and faculty. Results for all survey questions available in the supplement. |
Survey results and implications
Demographics
A total of 183 respondents completed the survey, with 163 identifying as non-tenure. The majority of respondents are students (38%) and postdocs (42%) from Europe (55%) and North America (33%; Fig. 1). Most respondents work with terrestrial (37%) or marine records (27%), or numerical models (23%). A larger proportion of respondents primarily collects or generates data (88%), rather than solely reanalyzing existing datasets (11%), for their research. Respondents commonly characterize their work as driven and dependent on quantitative data (60%). We use the survey results from the 20 tenured respondents as a point of comparison throughout the discussion below.
Data-sharing experience, opinions, and challenges
To facilitate reproducible science, Wilkinson et al. (2016) propose that published scientific data should be Findable, Accessible, Interoperable and Reusable (FAIR). Yet most non-tenured respondents (84%) are unfamiliar with the FAIR guiding principles for data management, a substantially higher proportion than in the tenured group (65%).
Tenured and non-tenured respondents equally feel that data (both 100%), metadata (both 90%) and code (e.g. data-analysis scripts; tenured: 65%; non-tenured: 70%) should be made publicly available and the proportion of respondents who regularly archive open data steadily increases from students (20%) to tenured researchers (80%; Fig. S10, supplementary information). More than two-thirds in all response groups most commonly utilize open databases or journal supplements (tenured: 72%; non-tenured: 65%) followed by personal or institutional databases (tenured: 18%; non-tenured: 12%, Fig. S11).
All respondents reported that a lack of metadata, inconsistent formatting, and data that are not centralized, not digitally available, or paywalled remain top challenges (Fig. S8). Yet, our results highlight that this problem may start at the ECR career stage: over half of the non-tenured respondents indicated “never” (12%) or “infrequently” (45%) adding metadata and code of their own to datasets, compared to 42% tenured respondents (Fig. S12). Our question on data-archival experience (Fig. S12) also reflected this split between ECR stages. If we eliminate respondents who answered “none of the above” because they had not yet published data, students were the largest group to report that the data-archiving process was difficult and the data archive they used lacked metadata templates, tutorials and upload scripts (63%). By comparison, tenured and later-stage ECRs noting this lack of guidance were less (22% each). Thus, unfamiliarity with metadata conventions and data-sharing standards may perpetuate the very problems that respondents identified in existing open datasets.
Data-sharing resources and training
The most common resources allocated to data sharing are time (tenured: 36%, non-tenured 19%) and staff help (tenured: 12%; non-tenured: 16%; Fig. S18). Over a third of the respondents that work in a lab (tenured: 36%; non-tenured: 48%) report that their lab is working towards standard operating procedures (SOPs), suggesting that labs do recognize a need for SOPs for data formatting and sharing. This is particularly important as our survey results signal that the most widespread issue may be related to labs without such SOPs (non-tenured: 89%, tenured: 78%; Fig. S17). More tenured (80%) than non-tenured (69%) respondents work in labs or institutions that offer no support for learning best practices for data sharing, or are not aware whether such support is available (Fig. 2b). Additionally, of the respondents who received training (26%), more than half feel that they need additional training.
Summary and recommendations
It is clear that the community recognizes the positive outcomes of an open-data culture: 95% of all non-tenured respondents and 90% of all tenured respondents feel that data sharing is advantageous to their career. However, equally pervasive are the difficulties surrounding open-access data preparation and publication as well as obtaining metadata-supported data (open-access or otherwise). Specifically, the lack of SOPs and institutional support paired with the unfamiliarity of best practices such as the FAIR guiding principles pose a challenge to data reusability. These benefits and challenges were widespread at all career stages.
Our survey targeting ECR practices and concerns highlighted that open-data usage tends to expand with career progression. We attribute that to researchers becoming more habituated to data-sharing procedures as they advance in their PhD programs, and career. Yet, we also found challenges unique to the ECR career stage:
• steep learning curve for new practitioners;
• widespread unfamiliarity with alternative data-sharing options such as data embargoes.
What can our community do to address these challenges for ECRs, and better promote open-data norms? ECRs working for senior (tenured) researchers may be in the position where their mentor is unfamiliar with the latest data-stewardship best practices, and thus either simply follow their mentor's practices, or must independently find other resources to support good data-sharing practices in their own work. Our survey results, however, suggest that data-management training initiatives (e.g. those offered by the Belmont Forum and Data Tree) are not widely used nor known. We therefore recommend dedicated community-led efforts to raise awareness and promote available training in data stewardship. Additionally, a continued discussion within the community regarding ways to motivate senior researchers and institutions to embrace community-wide data-sharing practices and SOPs will be key for establishing a culture of training ECRs in good data stewardship.
We therefore offer the following recommendations:
(1) Highlight existing resources, including FAIR, embargoes, and training available to ECRs (and other researchers).
(2) Encourage community efforts to the use of best practices in data stewardship and SOPs among ECRs, senior researchers and institutes.
We believe that the PAGES Early-Career Network (pastglobalchanges.org/ecn)can play an integral role in this movement by providing a platform for discourse within the community and a resource for data-stewardship training initiatives.
acknowledgements
Our questionnaire was generated using Qualtrics software, Version May, 2018. Qualtrics and all other Qualtrics product or service names are trademarks of Qualtrics, Provo, USA.
supplementary information
Access the whole survey summary here:
/download/docs/magazine/2018-2/ECR_Suppl_new_COPYREADY.pdf
affiliations
1Department of Geography, University College London, UK
2Climate Change Institute, University of Maine, Orono, USA
3Department of Environmental Sciences, Rutgers University, New Brunswick, USA
4Department of Geology, University at Buffalo, USA
5National Socio-Environmental Synthesis Center (SESYNC), University of Maryland, Annapolis, USA
6Department of Communication, University at Buffalo, USA
contact
Alexander Koch: alexander.koch.14ucl.ac.uk
references
Belmont Forum (2018) Retrieved August 6, from bfe-inf.org/action-theme-4-capacity-building-human-dimensions
Data Tree (2016) Retrieved August 6 from datatree.org.uk
Kaufman D, PAGES 2k Special Issue Editorial Team (2018) Clim Past 14: 593-600
PAGES Early-Career Network (2018) Retrieved July 6, from groups.google.com/forum/#!topic/pages-early-career-network/rOp6Hc7J6fc
Alicia J. Newton1,2
Every research paper is underlain by data. But, until relatively recently, the accessibility and archiving of this data has been an afterthought to the published paper. Technological advances and efforts to increase reproducibility have pushed data availability to the forefront.
Papers in the paleosciences have always been data rich: Emiliani’s (1955) work illustrating glacial-interglacial cycles relied on twelve cores sampled at 10 cm intervals. And from CLIMAP (Climate: Long range Investigation, Mapping, and Prediction) to PAGES 2k Network, paleoclimatologists have also been quick adopters of big-data approaches, combining individual records to generate global maps of temperature change through time. The value of these types of efforts is immediately recognizable by the wider paleo community. However, the open data practices that support these efforts have grown more slowly.
Today, the data that underlie the CLIMAP reconstruction are available from a variety of repositories found by a simple internet search. However, at the time of the compilation in 1981, files would have been shared peer to peer, with some smaller data tables contained within publications. Surprisingly, peer-to-peer sharing remains a prominent mode of data sharing, with 31% of Earth scientists opting not to archive data in a repository or include data in supplementary materials of publications (Stuart et al. 2018).
Peer-to-peer sharing is quick, but has a number of downsides. On a practical level, data that isn’t archived may be unprotected. Many scientists still store data on personal or external hard drives, where it is vulnerable to theft, format or program obsolescence, or simply an errant cup of coffee (Baynes 2017). On a broader level, requiring personal outreach to obtain data can hinder scientists with fewer connections or who face a language barrier. And data stored in this manner may be lost when scientists retire or leave academia.
In the paleosciences, and geosciences more broadly, data archiving in open repositories takes on an additional importance: it can be exceedingly expensive to obtain samples through means such as ocean or ice-core drilling, and materials such as meteorites or certain fossils can be extremely rare. And some samples may prove irreplaceable as material is lost through erosion, land-use changes, and as glaciers melt. As signatories to the Coalition on Publishing Data in the Earth and Space Sciences (COPDESS) Statement of Commitment (copdess.org/statement-of-commitment), publishers have recognized this importance.
Why open data?
 |
|
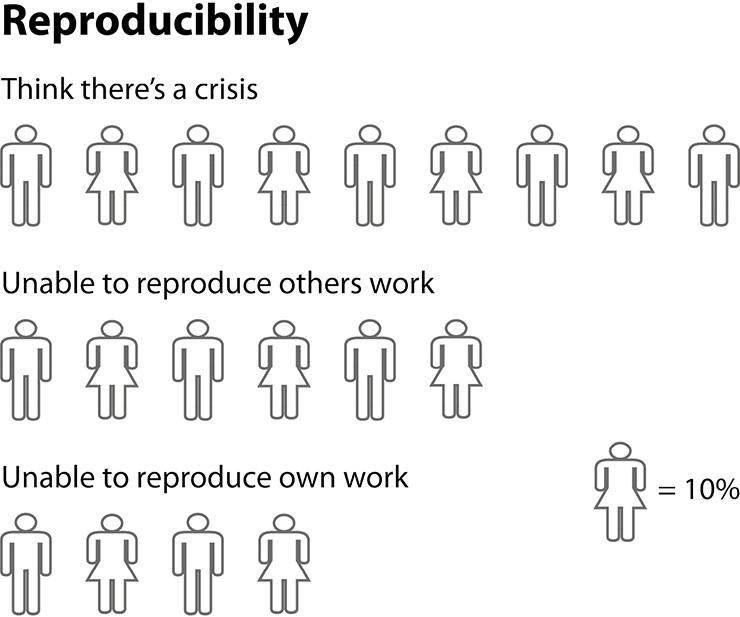
Figure 1: Respondents to a survey of 1,500 scientists raised substantial concerns about the reproducibility of the published literature, and reported their own experiences with failure to reproduce results (Baker 2016). Open data is one avenue being explored to help increase confidence in the scientific record. Image credit: Edwyn Mayhew. |
In 2016, 90% of researchers surveyed by Nature raised major concerns about the reproducibility of the scientific record, with few people convinced that all of the published literature would be reproducible (Fig. 1; Baker 2016). In the Earth and environmental sciences, about 40% of respondents were unable to reproduce even their own work in at least one instance; over 60% were unable to reproduce the findings of others. Increased openness of data, methods, and code can help improve confidence in the scientific record.
Geoscientists certainly recognize the importance of data sharing, with 69% of Earth scientists making their data available in a repository or supplementary materials (Stuart et al. 2018). This movement towards data availability is driven by a growing recognition that making supporting data open offers benefits for both data producers and the broader scientific endeavor (Schmidt et al. 2016). Specifically, data sharers are motivated by the desire to help accelerate scientific research, and also to increase the visibility and dissemination of their research output (Stuart et al. 2018). Intriguingly, the survey found that funder and publisher requirements were not as strong of an incentive to release data.
But is available data always open data? In the geosciences, 28% of respondents only made data available in the electronic supplementary materials (Fig. 2). Whether or not this material sits behind a paywall varies by publisher: Nature Geoscience and the Nature Research journals make this material free to read, but other journals require a subscription for access. The format and content of the supplementary-data tables may also be less than ideal, with pdf tables not always easy to import into other software.
Springer Nature has started a trial in which electronic supplementary materials from articles published in BioMed Central and Springer Open journals is hosted on Figshare. These files are freely accessible and uniquely identifiable with a separate DOI, helping the data behind a paper to find its own audience (Hyndman 2016).
Recognition and reward
Beyond altruism and a desire to contribute to scientific advances, there are other benefits for researchers who make their data widely available. In Paleoceanography, articles that were published alongside publicly-available datasets saw a 35% greater citation rate than the journal average (Sears 2011). Across all disciplines, data availability provides a citation boost between 9 and 50% (Baynes 2017).
The rise of peer-reviewed data journals helps to provide credit for data generators, beyond a traditional scientific publication. Journals like Scientific Data and Earth System Science Data publish “data descriptors”. These articles describe the collection and processing of a dataset that has been released through a public repository. The descriptors provide sufficient metadata and related information to allow for easy use of the data, but refrain from interpretation and extensive analysis. Data descriptors also can accompany a traditional scientific publication, and can allow for an expanded dataset to be released: for instance, δ13C data that was collected alongside oxygen isotopes but not featured in the interpretation or additional parts of a record that were generated but not the focus on the paper. In these instances, the data descriptor can have a different lead author than the main paper, perhaps giving due credit to a student researcher who led the data collection but played a smaller role in the interpretation.
Data-descriptor papers can also serve as a way to release and promote the reuse of datasets that might otherwise live in a proverbial desk drawer: data from student summer projects, null results, or the never-written up thesis chapter can all be released for others to work from and build upon. In these cases, the data generators can receive appropriate recognition for their work – and potentially the reward of citations of the data descriptor and data set – even if the interpretation of the data might not be sufficient to warrant a traditional publication.
Into the future
In 2015, COPDESS released a statement of commitment, which was signed by most Earth and environmental science publishers and data repositories. Signatories from the publishing side agreed to promote the use of appropriate community repositories to their authors, and direct authors to relevant resources, for instance through lists maintained at the COPDESS website. The statement also encouraged publishers to develop clear statements about requirements for data availability. The Nature Research journals have long required authors to make materials, data, and code available without undue qualification. Nature Research also encourages authors to freely release data through repositories (nature.com/authors/policies/availability.html). Data-availability statements, which are now available to readers without a subscription, tell readers how to access the data reported in the manuscript, as well as any previously published data used in the analysis (Nature 2016; Hrynaszkiewicz et al. 2016). Code-availability statements require authors to report whether any code associated with the work is accessible.
 |
|
Figure 2: How discoverable is the data behind a paper? Stuart et al. (2018) surveyed 365 Earth scientists about their experiences and if and how they made the data associated with their work available. Each folder represents 1% of the survey response. Image credit: Edwyn Mayhew. |
Of course, much of this data still remains in supplementary information (Fig. 2), and may be only partially accessible, or lacks the essential metadata and standardization that would be provided by curators at a repository. Led by AGU, some signatories to the original COPDESS statement are addressing this concern through the Enabling FAIR Data Project. This project, which is supported by Nature Research and other publishers, will support authors to make sure that the data behind their publications are Findable, Accessible, Interoperable, and Reusable (FAIR; Wilkinson et al. 2016). Importantly, the National Computational Infrastructure of Australia is also supporting the project, providing the expertise required to start to tackle the terabyte-sized elephant in the room that is model output.
Although these and other challenges remain, the combined efforts of funders, publishers, repositories, and open-data advocates are ushering in a new era of data openness. Open data helps ensure the integrity of the scientific record, while new metrics and venues ensure that data generators are recognized and rewarded for their work. And the community stands to benefit as well, as increasingly easy data access facilitates powerful big-data approaches to understanding past environments.
affiliations
1Nature Geoscience, Nature Research, London, UK
2Now at: The Geological Society of London, London, UK
contact
Alicia J. Newton: aliciajillnewtongmail.com
references
Baker M (2016) Nature 533: 454-454
Baynes G (2017) In: The state of open data 2017. Holtzbrinck Publishing Group, 17-19
Emiliani C (1955) J Geol 63: 538-578
Nature editorial staff (2016) Nature 537: 138
Schmidt B et al. (2016) PLOS one 11: e0146695
Stuart D et al. (2018) Practical challenges for researchers in data sharing. Figshare, paper
John W. Williams1,2, D.S. Kaufman3, A. Newton4,5 and L. von Gunten6
Open data advance the pace of discovery in the paleogeosciences. Community-curated data resources and data stewards, together, offer a solution for jointly maximizing the volume and quality of open data. All can assist, at both individual and institutional levels.
Open data, long a good idea, are now mission-critical to advancing and accelerating the pace and breadth of discovery in the paleogeosciences. We seek to understand the past dynamics of the Earth system and its interacting subsystems, across a wide range of timescales, and to use this knowledge to inform society in a new era of global change. However, the scale of the system is too vast, and the volume and variety of data too large, for any single investigator or team to be able to integrate it. Open scientific data, gathered into curated data resources, are essential to integrating this information at scales beyond the capacity of any single team. Such data can then support big-data applications, where inferential power is proportional to data size and richness, such as machine learning, proxy system modeling (Dee et al. 2016), and data-model assimilation (Hakim et al. 2016). Ultimately, the goal is to form an open architecture of scientific data as complex, deep, and interlinked as the Earth system itself.
The benefits of open data extend beyond scientific objectives. For individual investigators, open-data resources provide services of data archival and increasing data visibility. In the genetics literature, papers with published data have a 9% higher citation rate than similar studies without published data (Piwowar and Vision 2013). Open data enable interdisciplinary research and knowledge exchange across disciplines. Open data also empower early-career scientists and scientists from the Global South, enable transparency and reproducibility, and return the fruits of publicly and privately funded research to the public domain (Soranno et al. 2014).
Multiple initiatives are underway to support and encourage best practices in open data. Publishers have launched the FAIR initiative: data must be findable, accessible, interoperable, and reusable (Wilkinson et al. 2016). Funding agencies are setting firmer standards for publicly funded data (National Science Foundation 2018). Multiple authors have called for open data (Soranno et al. 2014; Schimel 2017; Kaufman and PAGES 2k special-issue editorial team 2018). Open code and software are becoming the norm, facilitated by open-source languages (e.g. R, Python), platforms for sharing code (e.g. GitHub, BitBucket), and notebooks for sharing scientific workflows (e.g. RMarkdown, Jupyter).
Nonetheless, both cultural and technical barriers remain (Heidorn 2008), with only 25% of geoscientific data submitted to open-data repositories (Stuart et al. 2018). Most scientists are willing to share data once published, but many lack the time to prepare datasets and metadata for open publication, or the training and tools to do so efficiently. Some communities lack established data standards and repositories, with particular difficulties in finding an appropriate home for terabyte-scale datasets. Systems for data citation and provenancing remain underdeveloped, so it is hard for scientists to receive the credit due for data publication. Data curation adds value to open data, thereby navigating the big-data challenge of maximizing both data volume and veracity (Price et al. 2018), but effective data curation requires dedicated time by experts, which needs to be recognized and rewarded. These challenges to open data are real but tractable and can be resolved through a combination of cultural and technological solutions.
 |
|
Figure 1: Community-curated data resources (CCDRs) as both social and technological solutions for supporting open data. Social characteristics include a shared scientific mission, communities of practice centered on domain experts, and governance mechanisms that facilitate participation and leadership by a broad and diverse base of experts. Technological characteristics include a central platform with support for uploading, curating, and providing data; and systems that facilitate open data access and data uploads. Because CCDRs are closely tied to their expert communities, they tend to be meso-scale intermediaries between individual data generators and big-data initiatives. |
One key emerging solution is the combined rise of community-curated data resources and linked networks of data stewards (CCDRs; Figs. 1, 2). CCDRs serve as loci where experts can contribute and refine data, establish data standards and norms, and ensure data quality. If open data are a commons, then CCDRs provide a governance framework for managing the commons. In this framework, data stewards (or data editors, see Diepenbroeck, this issue) are positions of service and leadership that are equivalent in function and prestige to journal editors, dedicating a portion of their time and expertise to ensure that published data are of high quality and meet community standards. The broader cultural goal is to establish norms of data openness – in which we commit to contributing our data to community data resources – and data stewardship, in which we commit to adding value to community data resources on an ongoing basis.
Multiple related initiatives are underway to build open and high-quality community data resources, stewarded by experts. Publishers have created journals specifically devoted to data publication (Newton, this issue). In paleoclimatology, PAGES 2K has established pilot examples of open data and data stewardship for global-scale data syntheses (PAGES 2k Consortium 2017). The LiPD and LinkedEarth ontologies provide flexible data standards for paleoclimatic data, with editors able to approve ontology extensions (McKay and Emile-Geay, this issue). The Neotoma Paleoecology Database has established a system of member virtual constituent databases, each with data stewards charged with prioritizing data uploads and defining variable names and taxonomies (Williams et al. 2018). The Paleobiology Database uses data authorizers to ensure quality data uploads (Uhen et al. 2013 and this issue). Some efforts focus on curating primary measurements and others on higher-level derived inferences (McKay and Emile-Geay, this issue).
 |
|
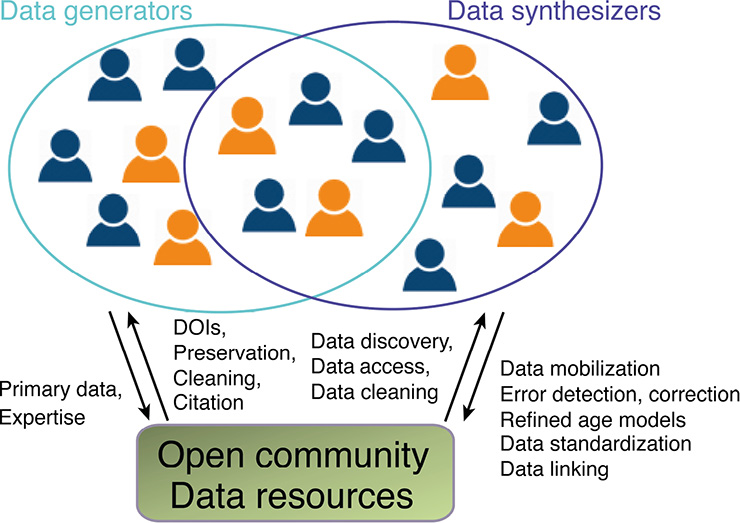
Figure 2: Paleodata CCDRs and their relationships of engagement with their overlapping research communities of data generators, stewards, and synthesizers. Data generators provide the primary data to CCDRs and receive in return DOIs for data citation and tracking and assistance in meeting community data standards. Synthesizers benefit from CCDRs through the services of improved data discovery, access, and cleaning, while returning to CCDRs the services of data mobilization for dark data, detection and correction of errors in CCDRs, updated and improved age models, and assistance in linking CCDRs with other data resources. Data stewards (orange), drawn from both communities, support data curation and ensure that community data norms are met, akin to the role of editors in peer-reviewed journals. |
Technologically, the broad need is to move open-data resources from systems of record to systems of engagement (Moore 2011), in which we move beyond models of submitting datasets to static data repositories to systems that support crowdsourcing and ongoing efforts to publish and improve data. Such infrastructure must support data discovery, archival, citation, tracking, annotation, and linking. Flexible and extensible data models are needed to support both existing and new proxies (McKay and Emile-Geay, this issue). Controlled vocabularies and common semantic frameworks are needed to tame the heterogeneity of proxy measurements. Systems for data annotation are needed to flag and correct data errors. Systems for microattribution and provenancing are needed to track data usage from initial publication to subsequent incorporation into broad-scale data syntheses. Assigning DOIs to datasets is a first step; subsequent steps are to include these DOIs in all future publications to appropriately credit data generators. Journals and citation indices will need to adopt linked data systems, tracking data usage, with ability to link to thousands of individual records, so as to avoid arbitrary limits caused by fixed limits to the number of references. New tools are needed that streamline the collection and passing of data from point of collection to data resource. Because effort is the main barrier to open data, good data management should be maximally automated.
For open data to power the next generation of scientific discovery, we must all pitch in. Scientists must commit to making their data available in open public repositories, join governance, and serve as data stewards. Publishers, as they adopt FAIR data standards, should endorse and support open community data resources that meet these standards. Funding agencies should support development of open-data standards for data types where none yet exist and provide modest but sustained support for open-data resources, under the logic that costs of supporting CCDRs are cheap relative to costs of regenerating primary data. We must launch data-mobilization campaigns that are science driven (e.g. PAGES 2k Consortium 2017), using these campaigns to prioritize rescues of dark data. Professional societies should establish mechanisms to endorse community data standards and open platforms and, where possible, provide support via a portion of membership dues. Just as professional journals were the mainstay of communicating scientific knowledge in the 19th and 20th centuries, open, high-quality community data resources will be a mainstay of communicating and advancing knowledge in the coming decades.
affiliations
1Department of Geography, University of Wisconsin-Madison, USA
2Neotoma Paleoecology Database
3School of Earth and Sustainability, Northern Arizona University, Flagstaff, USA
4Nature Geosciences Editorial Office, London, UK
5Geological Society of London, UK
6PAGES International Project Office, Bern, Switzerland
contact
John (Jack) W. Williams: jwwgeography.wisc.edu
references
Dee SG et al. (2016) J Ad Model Earth Sy 8: 1164-1179
Hakim GJ et al. (2016) J Geophys Res Atmos 121: 6745-6764
Heidorn PB (2008) Libr Trends 57: 280-299
Kaufman DS, PAGES 2k special-issue editorial team (2018) Clim Past 14: 593-600
PAGES 2k Consortium (2017) Sci Data 4: 170088
Piwowar HA, Vision TJ (2013) PeerJ 1: e175
Price GJ et al. (2018) Nature 558: 23-25
Schimel D (2017) Front Ecol Environ 15: 175
Soranno PA et al. (2014) BioScience 65: 69-73
Stuart D et al. (2018) Practical challenges for researchers in data sharing. SpringerNature, 17 pp
Uhen MD et al. (2013) J Vert Paleontol 33: 13-28

John W. Williams1,2, D.S. Kaufman3, A. Newton4,5 and L. von Gunten6
Open data in the paleogeosciences have a long and fruitful history. Many of the primary open-data resources in the paleoenvironmental sciences are now at least two decades old, including the NOAA World Data Center for Paleoclimatology (Gross et al., p. 58), PANGAEA (Diepenbroek, p. 59), Paleoclimate Modelling Intercomparison Project (PMIP, Peterschmitt et al., p. 60), and the Paleobiology Database (Uhen et al., p. 78), all founded in the 1990s, with others, such as the Neotoma Paleoecology Database (Grimm, p.64), tracing their roots to constituent databases from this era and to influences spanning the last century. Indeed, this special issue can be viewed as a 20th-anniversary celebration of the 1998 "Paleodata" issue of PAGES news (the former name of Past Global Changes Magazine) that established many of the advances reviewed here (PAGES IPO 1998).
The history of open data in the paleogeosciences is long because the scientific motivation is so clear and unambiguous. In the large, complex, and ever-changing Earth system, scientific insight requires the open availability and close integration of multiple observational systems with Earth system models, to better understand the past and present, and better forecast the future (Crucifix 2012; Dietze et al. 2018). And, as the Great Acceleration continues (Steffen et al. 2015), such efforts have increased urgency; the past offers a uniquely important set of model systems for the strange new world of the coming decades.
Over these last two decades of open data, much has changed. The dividing line between “data generator” and “data user”, so apparently bright in the 1990s (PAGES Scientific Steering Committee 1998), has blurred as a new generation has arisen, with cross-over expertise in data generation, synthesis, and modeling. The information revolution races on, with the data sciences emerging both as a distinct academic discipline (Blei and Smyth 2017) and as a key employment opportunity for many scientists. Access to open-data resources is now essential to career advancement for early-career scientists, while lack of access to training is a key barrier (Koch et al., p. 54).
Contributing one's data to open-data resources, once largely voluntary, is now required by most journals, funders, and professional societies (Newton, p. 52; Belmont Forum, p. 56). The bar has been raised for open-data resources, to ensure that they meet the FAIR standards of Findable, Accessible, Interoperable, and Reusable (PAGES Scientific Steering Committee, p. 48; Gross, p. 58). New funding initiatives are being launched to increase the power and interoperability of existing data resources (e.g. NSF's EarthCube; Belmont Forum, p. 56), leading to new and flexible data standards and software that leverage and link open-data resources (Uhen et al., p. 78; McKay and Emile-Geay, p. 71). New geovisualization approaches such as Flyover Country, using open data and mobile technologies, are bringing paleodata to new audiences (Myrbo et al., p. 74). And, our understanding of data is changing as well, as we recognize that open data require ongoing curation and improvement, supported by community-curated data resources and linked networks of data stewards (Williams et al., p. 50).
These advances in open-data systems are opening up new scientific frontiers. Data-model assimilation, in which paleoenvironmental inferences from data and models are closely integrated, weighted by uncertainty, are active fields in paleoclimatology (Hakim et al., p. 73) and paleoecology (McLachlan and the PalEON Project, p. 76). Computer scientists are experimenting with artificial-intelligence approaches to age-model development (Bradley et al., p. 72) and extracting geological knowledge from the peer-reviewed literature (Marsicek et al., p. 70). Open paleodata have reached new audiences, as biogeographers and macroecologists combine the fossil record with big-data genetic repositories to study the processes governing the distribution and diversity of life (Fordham and Nogues-Bravo, p. 77), and as archaeologists bring big data to bear on the interplay between humans and the environment (Kohler et al., p. 68).
More needs to be done. Many key data remain "dark", requiring inordinate effort to gather and synthesize (Stenni and Thomas, p. 66). The paleoscience communities need to commit to conventions for reporting data and essential metadata, with shared adoption by scientists, data resources, publishers, and funding agencies. Established open-data resources need commitments of sustained support from funding agencies, with opportunities to build new data resources or extend existing data models to serve new kinds of data and science. The recent advances in assigning digital object identifiers (DOIs) to datasets needs to be more fully leveraged so that data generators are appropriately credited for data use. Scientific data services are needed that better streamline the passing of data from individual labs to community data resources. And, most of all, we need better integrated training programs in paleoscience and data science, to train the next generation of cross-over scientists.
In short, these are exciting and changing times. This special issue is more progress report than final authority. Nevertheless, we hope that the articles enclosed will provide useful information about the latest updates from some of the major open-data resources in the paleogeosciences, the efforts to build new resources and interlink existing resources, the emergence of new software and science powered by open data, and the ever-evolving interplay among cultural norms, technological advances, and scientific discovery.
affiliations
1Department of Geography, University of Wisconsin-Madison, USA
2Neotoma Paleoecology Database
3School of Earth and Sustainability, Northern Arizona University, Flagstaff, USA
4Nature Geosciences Editorial Office, London, UK
5Geological Society of London, UK
6PAGES International Project Office, Bern, Switzerland
contact
John (Jack) W. Williams: jwwgeography.wisc.edu
references
Blei DM, Smyth P (2017) PNAS 114: 8689-8692
Crucifix M (2012) Quat Sci Rev 57: 1-16
Dietze MC et al. (2018) PNAS 115: 1424-1432
PAGES IPO (1998) PAGES news 6(2)
PAGES Scientific Steering Committee (1998) PAGES news 6(2): 1-2
PAGES Scientific Steering Committee*
 |
|
Figure 1: 1998 winter issue of PAGES news, with the PAGES SSC editorial on data stewardship. |
The last time Past Global Changes Magazine highlighted the power of open paleodata was exactly 20 years ago. The cover page of the winter 1998 issue (PAGES IPO 1998; Fig. 1) featured an editorial by the PAGES Scientific Steering Committee (1998) entitled, “Responsibilities of Data Sharing and Data Use.” Our predecessor Scientific Steering Committee members anticipated that open paleodata would fuel discoveries in past global changes. Their initiative has grown into the ongoing PAGES Data Stewardship Integrative Activity1, and led to our recent alliance2 with other international scientific organizations in efforts to make data publicly accessible. The 1998 editorial laid the groundwork for the first PAGES data policy by encouraging the transfer of “the highest possible proportion of existing and new, high-quality data into public domain databases…” so that access to data “…is truly easy and open to all.”
We are announcing updated and expanded procedures3 for making data available, with the goal of maximizing the long-term scientific benefit of the data generated as part of all PAGES-related activities, while fulfilling PAGES’ obligation to its funders. The new PAGES guidelines build on the earlier policy and are reinforced by the FAIR (findable, accessible, interoperable, and reusable) data stewardship principles (Wilkinson et al. 2016), which have been endorsed by scientific organizations globally. They focus on publications and are adapted for paleoscience from the Author Guidelines4 that are now being implemented by all major publishers of Earth and Space Sciences, as motivated by the Enabling FAIR Data Project5. They have benefited from input from managing and chief editors of paleo journals, repositories, and the community. For example, the new procedures now provide guidelines on the use of data embargoes, a topic that emerged from the paleoscience community open discussion6 as part of the PAGES 2k open-paleodata implementation pilot (Kaufman and PAGES 2k special-issue editorial team 2018).
The 1998 editorial also called for new “realistic ways of both recognizing and rewarding the generosity of all who submit their data.” The importance of crediting data generators and the value of making data reusable for future scientists is now being addressed with the advent of data citations and journals dedicated to data products. PAGES encourages the use of data citations7, which are analogous to standard bibliographic citations, but give explicit credit to data producers, with greater exposure and citation of their work. For large-scale synthesis products, PAGES promotes the use of data-oriented publications as a means to including many data generators in the production of value-added, high-visibility data products, with inclusive authorship.
In addition to new avenues for crediting data generators, attitudes toward open data have evolved over the past two decades, and they evolve with individual’s careers. Unfortunately, data that are not properly curated are liable to be lost to subsequent reuse; the time comes too quickly when the data that were made “available upon request” may never be discovered or used in future studies; a true loss for all. Now, with new means for making data available, the rewards, including higher citation rates and other benefits described by Newton (p. 52), are proportionally greater. Scientists, especially those early in their career, seek to increase the impact and recognition of their research by facilitating the reuse of their results. Indeed, according to the survey conducted by the PAGES Early-Career Network (Koch et al., p. 54), 95% of the 163 non-tenured respondents feel that data sharing is advantageous to their careers.
We recognize that data stewardship requires substantial effort, but we are convinced that the benefits outweigh the (perceived) costs. It is increasingly obvious that the future of our field depends on robust and widely adopted data-sharing practices and procedures. We appreciate the community’s foresight and dedication to data that are open and reusable, while curtailing the loss of valuable data.
*PAGES scentific steering committee
A. Asrat (Addis Ababa University, Ethiopia); P. Braconnot (Lab. des Sciences du Climat et de l’Environnement, Gif-Sur-Yvette; E. Brook (Oregon State University, USA); E. Capron (British Antarctic Survey, UK); C. Chiesi (University of São Paulo, Brazil); M.N. Evans (University of Maryland, USA); P. Gell (Federation University Australia, Australia); L. Gillson (University of Cape Town, South Africa); H. Goosse (Université catholique de Louvain, Belgium); Z. Jian (Tongji University, China); D.S. Kaufman (Northern Arizona University, USA); M. Kucera (University of Bremen, Germany); K. Meissner (University of New South Wales, Australia); W. Tinner (University of Bern, Switzerland); B.L. Valero-Garcés (Spanish National Research Council, Spain); Y. Yokoyama (University of Tokyo, Japan).
contact
Darrell S. Kaufman: Darrell.Kaufmannau.edu
references
PAGES IPO (1998) PAGES news 6(2)
PAGES Scientific Steering Committee (1998) PAGES news 6: 1-2
Kaufman DS, PAGES 2k special-issue editorial team (2018) Clim Past 14: 593-600
Wilkinson MD et al. (2016) Sci Data 3: 160018
links
1pastglobalchanges.org/ini/int-act/data-stewardship
2pastglobalchanges.org/news/2062-pages-data-agreements-aug-18
3pastglobalchanges.org/data/data-guidelines
4copdess.org/enabling-fair-data-project/author-guidelines/
5copdess.org/enabling-fair-data-project/
Julius B. Lejju and Andama Morgan
5th EAQUA Workshop, Mukono, Uganda, 4-7 July 2017
The 5th East African Quaternary Research Association (EAQUA) workshop was themed “Decades of Quaternary Research in Eastern Africa: Implications for Sustainable Future”. It was intended to foster ways of integrating the long-term scientific information of various paleo studies in eastern Africa from the last six decades to address future environmental challenges in the region. In addition, the workshop was meant to integrate the rich paleo information into practical applications to address the social and environmental challenges affecting the region.
The workshop was attended by over 60 research scientists from Eastern Africa, Ethiopia, Malawi, West Africa, Southern Africa, Europe and USA. More than 40 research papers were presented under several sub-themes that addressed the rich Quaternary environments of eastern Africa. The sub-themes included Regional Climate Dynamics for Eastern Africa; Quaternary Human-Environment interactions in Eastern Africa; Anthropology, Archaeology and Paleontology in Eastern Africa; Natural and Cultural Heritage in Eastern Africa; and Paleoscience in other regions of Africa. The keynote papers reviewed the long-term environmental dynamics of the region, and presented the output of 30 years of paleontological research in Eastern Africa, in particular from the Napak region in Uganda, which yields immense paleo information with significant deposits of fossil records spanning the last 20 Ma. While the region is covered by Savanna nowadays, geological studies have revealed evidence of patchily distributed flowing rivers and streams, including swamps 20 Ma ago. Furthermore, the discovery of remains of the extinct genus of hominoid primate Ugandapithecus and the assemblages of land snails indicate the presence of a tropical rainforest. Aquatic fossil remains suggest the presence of fresh water bodies.
 |
|
Figure 1: Source of the Nile at Jinja, Uganda. |
East Africa is believed to be the origin place of humankind, as most of the early hominid fossils were found in this region. When East Africa became drier in the Late Miocene, animals already adapted to a drier environment in the South dispersed to East Africa. The development of the Cenozoic East African Rift System, which greatly re-shaped the landscape of the region, triggered the early hominin evolution and also led to the formation of isolated rift lakes and development of amplifier lakes (Trauth et al. 2010) in the basins three million years ago. The tectonic activity significantly contributed to the exceptional sensitivity of Eastern Africa to climate change, compared to other parts of the African continent. Thus, the last two Ma in East Africa are characterized by variable climate conditions with high fluctuating lake levels (Fig. 1) and complete desiccation of Lake Victoria during the late Pleistocene. The West Nile sector of the Albertine Rift contains fossiliferous Mio-Pliocene deposits, similar in age to parts of the succession in Kenya, where early evidence of bipedal hominids was discovered.
Climate change in the past and the consequential ecosystems changes have been seen to play a critical role in shaping the evolution trajectories in East Africa. Recent climatic variations in the region at decadal and centennial scales are characterized by strong rainfall seasonality resulting from the annual migration of the Intertropical Convergence Zone. This interannual variability is also linked to other mechanisms such as sea-surface temperature anomalies attributed to the Indian Ocean Dipole and El Niño/Southern Oscillation. The East African region is also known for the existence of rock art sites coupled with lithic fragments and pottery - an indication of the presence of hunter-gatherer systems.
The paleo data of this workshop will be integrated in the assessment of future issues in the region and the proceedings of this workshop will be published as a special issue in a peer-reviewed journal.
affiliation
Department of Biology, Mbarara University of Science & Technology, Uganda
contact
Julius B. Lejju: jlejjumust.ac.ug
references
Rachid Cheddadi1, I. Bouimetarhan2, M. Carré3, A. Rhoujjati4, A. Benkaddour4 and M. Nourelbait1
Marrakesh, Morocco, 6-11 November 2017
Climate changes in Africa have a tremendous impact on ecosystems and human societies. Climate change-related risks are aggravated in Africa by the deficient data availability and research efforts which create major knowledge gaps and uncertainties.
In an attempt to build synergy and promote climate change research in Africa, the multi-disciplinary conference CCA2017 (Climate Change in Africa, vulpesproject.wix.com/workshop) was organized at the Cadi Ayyad University of Marrakesh.
The primary goal was to gather scientists from complementary disciplines including Earth sciences, (paleo-)oceanography, (paleo-)climatology, climate modeling, ecology, and archaeology, for a multidisciplinary assessment of the latest results and to start discussions related to climate change and its impacts, from past natural variability to modern changes and future projections.
 |
|
Figure 1: Will the ongoing climate change in Africa lead to an extinction of some endemic species (Cheddadi et al. 2017)? |
CCA2017 was attended by 80 delegates from 20 countries including eight African countries (Algeria, Benin, Cameroon, Congo, Morocco, Senegal, South Africa and Tunisia). Travel support was offered by PAGES for three African early-career scientists who presented their work in both posters and oral presentations. The conference consisted of five sessions: (1) on climate change mechanisms in Africa including links between orbital forcing and inter-annual rainfall variability, extreme precipitation over Africa, dust fluctuations during the African Humid Period, predicting the Sahel summer rainfall, and the variability of the West African monsoon; (2) dedicated to the climate impacts on eco- and agro-systems. This session gathered presentations on the cultural resilience of the NE Sahara facing problems of surface water storage, the sustainability and resilience in the Congo Basin, the conditions under which forests grow in Central Africa, the impacts on ecosystem functions and services in Sub-Saharan Africa, the history of mountain forests in central Africa, and finally the use of plant DNA to explore the imprints left by past climate changes in Tropical flora; (3) on tropical teleconnections and monsoon systems, which showcased talks on precipitation responses during recent El Niño events, the teleconnection patterns during the last millennium in NW Africa, the trends, rhythms and transitions in East Africa, and the anthropogenic impact on the Sahel climate; (4) dedicated to the Mediterranean region presenting the past droughts and flooding in the Levant, the climate conditions around the Red Sea and Dead Sea during the Last Interglacial, the timings and mechanisms of Holocene environmental changes in Morocco (Fig. 1) and Tunisia, the role of microclimates in preserving plant species in microrefugia, as well as how to predict plant species, future range using vegetation modeling; (5) focused on land-ocean links including oceanic variability in the southern Benguela upwelling system and their implications for increased Agulhas leakage during the late Holocene, the seasonal sea surface temperatures off South Africa, climate variability and its driving forces in southern Africa, and the vegetation dynamics during the Holocene in Benin.
The three-day meeting was followed by a two-day field excursion into the Moroccan desert in which 35 delegates took part. This was a fantastic opportunity to pursue scientific discussions while experiencing one of the most extreme environments on Earth.
The group strongly felt that although climate mechanisms and impacts can be partially studied by the international community without ever being in Africa, all climate change studies ultimately rely on field data. We therefore call for an increased international scientific effort toward field science involving institutional cooperation with local scientists.
affiliations
1ISEM, University of Montpellier, France
2MARUM, University of Bremen, Germany
3LOCEAN Laboratory (CNRS-IRD-MNHN), Sorbonne University, Paris, France
4Faculty of Sciences and Techniques, Cadi Ayyad University, Marrakech, Morocco
contact
Rachid Cheddadi: cheddadi.rcgmail.com
references